
The National Alliance for Health Information Technology Report to the Office of the National Coordinator for Health Information Technology on Defining Key Health Information Technology Terms
Basically, it has some interesting definitions for some common healthcare terminology. The location of the original document (along with the rest of the NAHIT site) appears to be down at the moment, but John Mertz at NeoTools has conveniently listed the terms for us, so I'll repeat them here:
- Electronic Medical Record: An electronic record of health-related information on an individual that can be created, gathered, managed, and consulted by authorized clinicians and staff within one healthcare organization.
- Electronic Health Record: An electronic record of health-related information on an individual that conforms to nationally recognized standards and that can be created, managed, and consulted by authorized clinicians and staff across more than one healthcare organization.
- Personal Health Record: An electronic record of health-related information on an individual that conforms to nationally recognized interoperability standards and that can be drawn from multiple sources while being managed, shared, and controlled by the individual.
- Health Information Exchange: The electronic movement of health-related information among organizations according to nationally recognized standards.
- Health Information Organization: An organization that oversees and governs the exchange of health-related information among organizations according to nationally recognized standards.
- Regional Health Information Organization: A health information organization that brings together health care stakeholders within a defined geographic area and governs health information exchange among them for the purpose of improving health and care in that community.

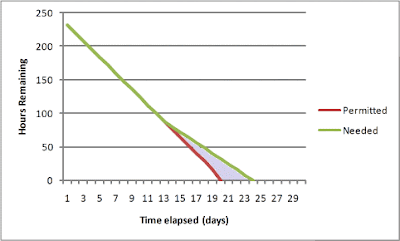 In this chart, the project was expected to be completed in about 20 days. About 13 days into the project, it became clear that an additional 4-5 days would be required to complete it in a high-quality way. However, a business decision was made to stick to the original schedule by working more hours, cutting corners, or making some other compromise.
In this chart, the project was expected to be completed in about 20 days. About 13 days into the project, it became clear that an additional 4-5 days would be required to complete it in a high-quality way. However, a business decision was made to stick to the original schedule by working more hours, cutting corners, or making some other compromise.